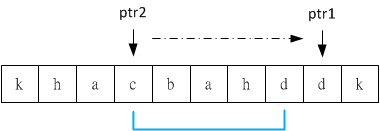
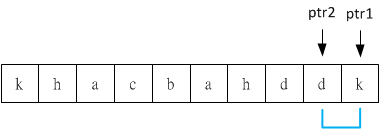
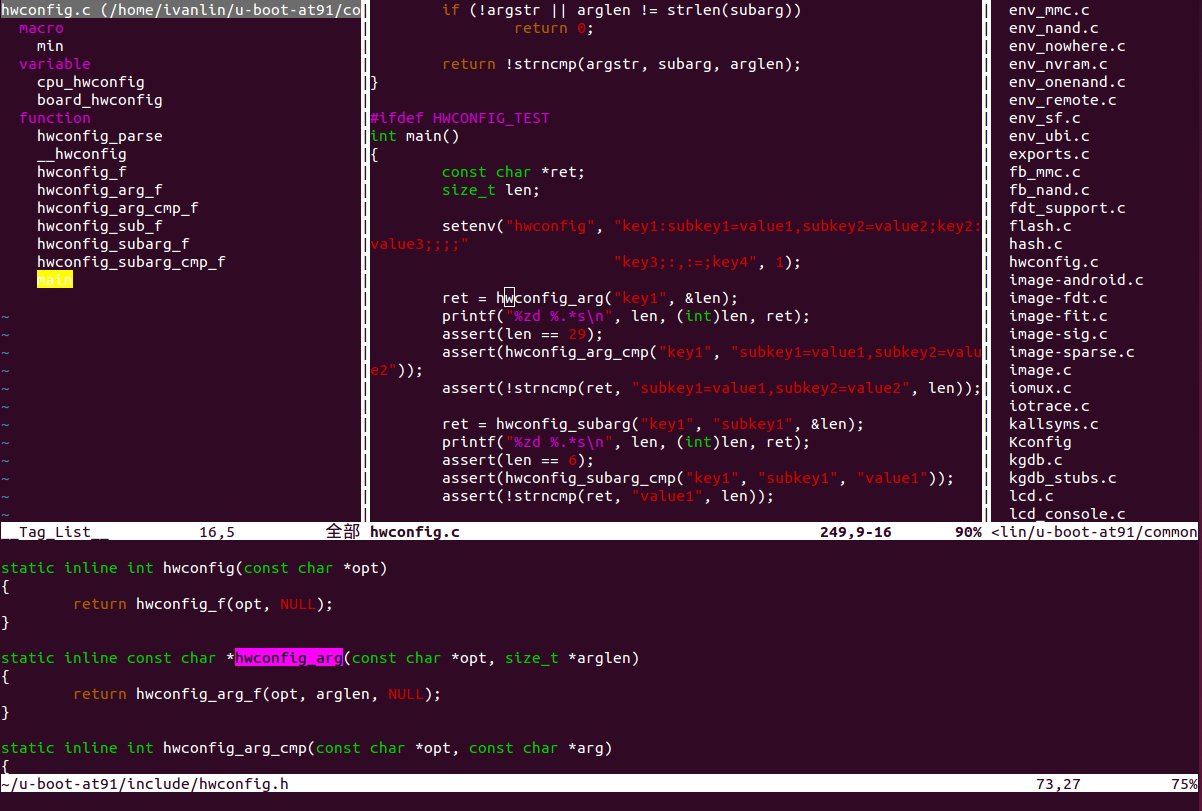
less是在Linux平台下經常用來觀看檔案內容的工具,不過當在看code時少了syntax highlighting會比較不好閱讀,若想要在less底下也可以有此效果,那可以裝GNU提供的Source-highlight
GNU Source-highlight
相關資訊可參考
https://www.gnu.org/software/src-highlite/
- 安裝
使用的平台為ubuntu,安裝時輸入
sudo apt install libsource-highlight-common source-highlight
成功的話應可以在/usr/share/底下看到source-highlight資料夾
- 使用
參考如下
export LESSOPEN="| /usr/bin/src-hilite-lesspipe.sh %s"
export LESS=' -R '
之後使用less看code時就會有syntax highlighting了